

Every AI product launched in the last two years has the same pitch: talk to it. Ask it questions. Give it prompts. The interface is always a conversation.
But there’s a different way to think about intelligence in software — one that doesn’t involve a chat box at all.
Imagine a forest. You place a jaguar, a few rabbits, some ferns, a colony of bees, and a patch of mycorrhizal fungi into a virtual clearing. You press a button that says “Become Alive.” And then you watch.
The jaguar gets hungry. It starts to hunt. The rabbits scatter. The ferns grow toward the light, drawing nutrients from the soil until the voxels beneath them start to dry. The bees find a fruiting plant and pollinate it. The fungi quietly decompose a fallen leaf, recycling its nutrients back into the earth. The soil changes. The plants respond. The animals adapt.
None of this was scripted. No one animated these behaviors. No one wrote a decision tree for the jaguar.
Instead, a small neural network — running on a server somewhere in the cloud — is watching the state of every living thing in this ecosystem and making thousands of tiny inferences per second. It sees that the jaguar’s hunger variable has crossed a threshold. It sees that the rabbit is within sensory range. It computes a four-dimensional motion vector that encodes not just where the jaguar should move, but how — urgently, cautiously, or lazily, depending on its energy level and the temperature of the biome.
The client — a game engine rendering the scene — never sees the math. It receives a small packet of numbers and translates them into smooth, lifelike motion. The simulation logic and the visual presentation are completely decoupled. The server is the brain. The client is the body.
This is what I mean by the unseen hand.
Small models, not large ones
The models doing this work are tiny. We’re talking about four-layer neural networks with a few thousand parameters — the kind you could train on a laptop in an afternoon. They’re not generating text. They’re not reasoning about philosophy. They’re doing one very specific thing: mapping a context vector (hunger, energy, temperature, humidity, species type) to a motion descriptor (a compressed representation of how a creature should move).
This is the part that most people miss about the current AI moment. The headlines are all about frontier models — systems with hundreds of billions of parameters that can write essays and pass bar exams. But the vast majority of useful AI in the real world will be small, specialized, and invisible. A 4-dimensional latent vector guiding the gait of a virtual animal. A tiny regression model predicting soil nutrient depletion rates. A lightweight inference engine deciding when a plant transitions from “growing” to “fruiting.”
These models don’t need to be smart. They need to be fast, cheap, and correct enough to make the world around you feel coherent.
The architecture of invisibility
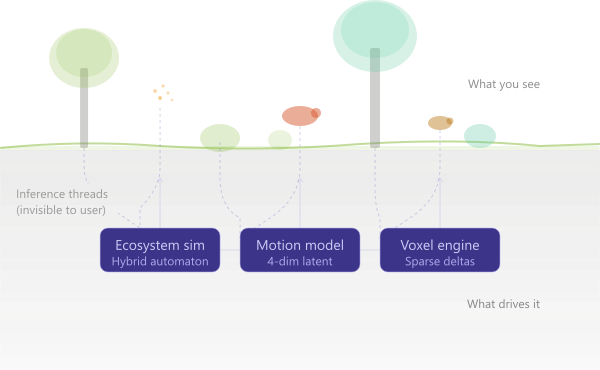
The system behind this has three layers, and the user only ever sees one of them.
The visible layer is a game engine — in our case, Godot 4 — rendering trees, animals, terrain, and particle effects. It handles interpolation, animation blending, and shader-driven environment visualization. It makes things look alive.
The simulation layer is a hybrid automaton running in the cloud. It maintains the “ground truth” of the ecosystem: continuous state variables (hunger rises, hydration falls, nutrients deplete) governed by differential equations, plus discrete state transitions (idle → foraging → hunting → resting) triggered by guard conditions. This is classical control theory, not machine learning — but it provides the substrate that ML operates on.
The inference layer is where the small models live. They sit between the simulation and the client, translating raw state vectors into motion descriptors that the client can interpret aesthetically. The simulation says “this jaguar is hungry and moving toward prey.” The model says “the way it moves should feel urgent and low to the ground.” The client receives a four-element vector and blends it against a motion database to produce animation that feels intentional, not random.
The key insight is the decoupling. The server doesn’t know about bones or animation clips. The client doesn’t know about hunger thresholds or nutrient chemistry. They communicate through a thin protocol of delta-encoded state updates and compact latent vectors. The bandwidth cost is trivial — a few hundred bytes per tick. The computational cost is a single forward pass through a tiny network.
Why this matters beyond games
This pattern — small models, invisible inference, decoupled rendering — isn’t limited to virtual ecosystems. It’s a template for any system where you want intelligence to guide behavior without the user being aware of it.
Smart buildings where a tiny model adjusts airflow based on occupancy patterns and CO₂ levels, and the occupants just notice that the room always feels comfortable. Agricultural systems where a lightweight network predicts soil depletion from sensor data and adjusts irrigation before the farmer sees wilting.
In all of these cases, the AI isn’t the product. The AI is the hand you never see, making the product feel like it understands the world.
The foundation model question
The motion model in our ecosystem currently uses stylized motion capture data with weights that produce latent vectors. Turning it into something more meaningful requires better training data: pairs of biological context vectors and corresponding motion descriptors extracted from real animation data. This is a foundation model problem, but not in the way people usually mean that phrase.
Foundation models for language need trillions of tokens. Foundation models for motion need a few thousand carefully labeled animation clips. The model itself has four layers and fit in a few kilobytes. But the impact of getting those four latent dimensions right is enormous — it’s the difference between a virtual animal that moves like a puppet and one that moves like it’s alive.
The unseen hand doesn’t need to be large. It just needs to know exactly where to push.
This is part of an ongoing project building a distributed ecosystem simulation. The server runs a hybrid automaton engine with ML-driven motion inference; the client renders in Godot 4.x. If you’re interested in the technical details or want to follow the build, subscribe and I’ll share the architecture and code as we go.